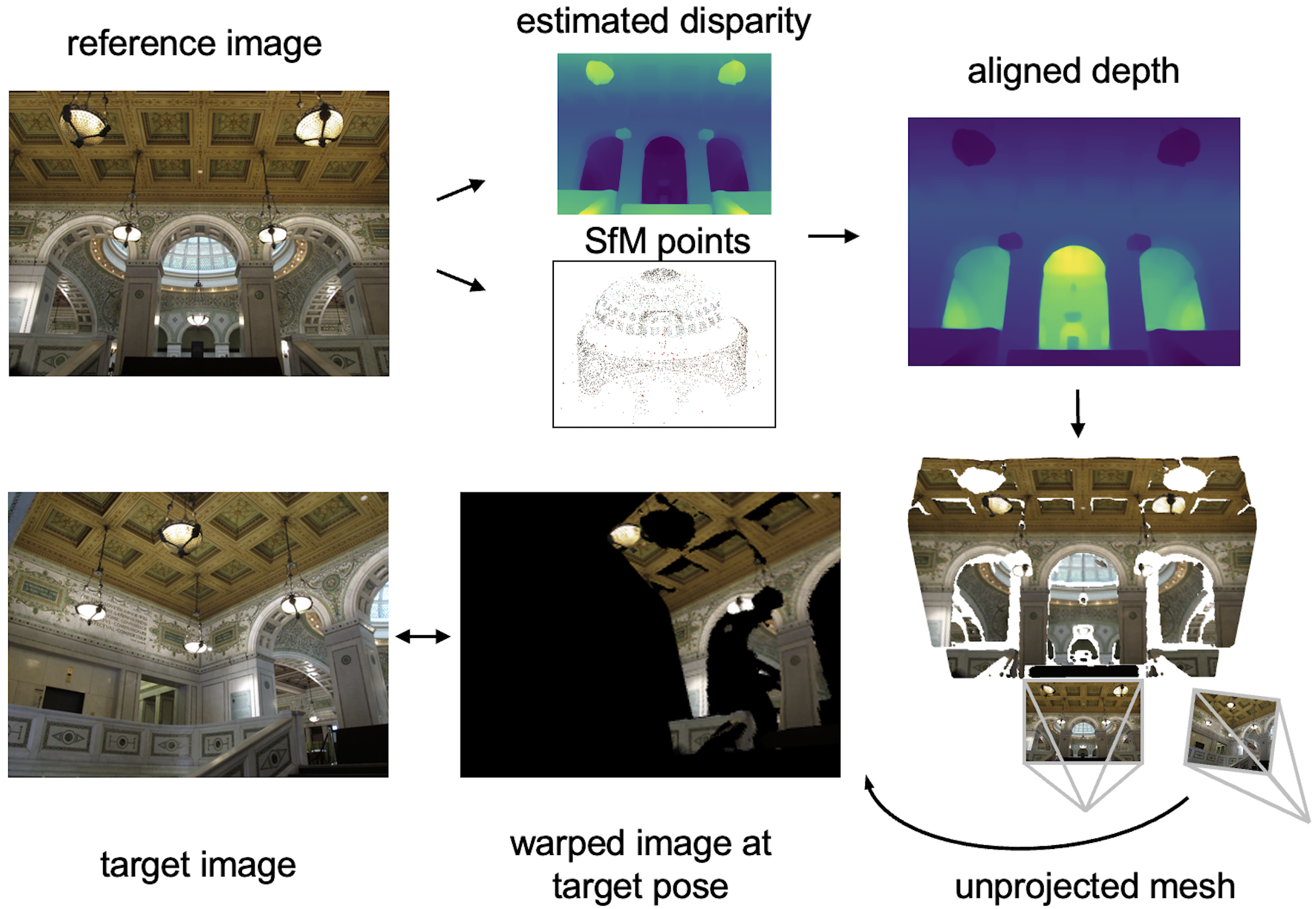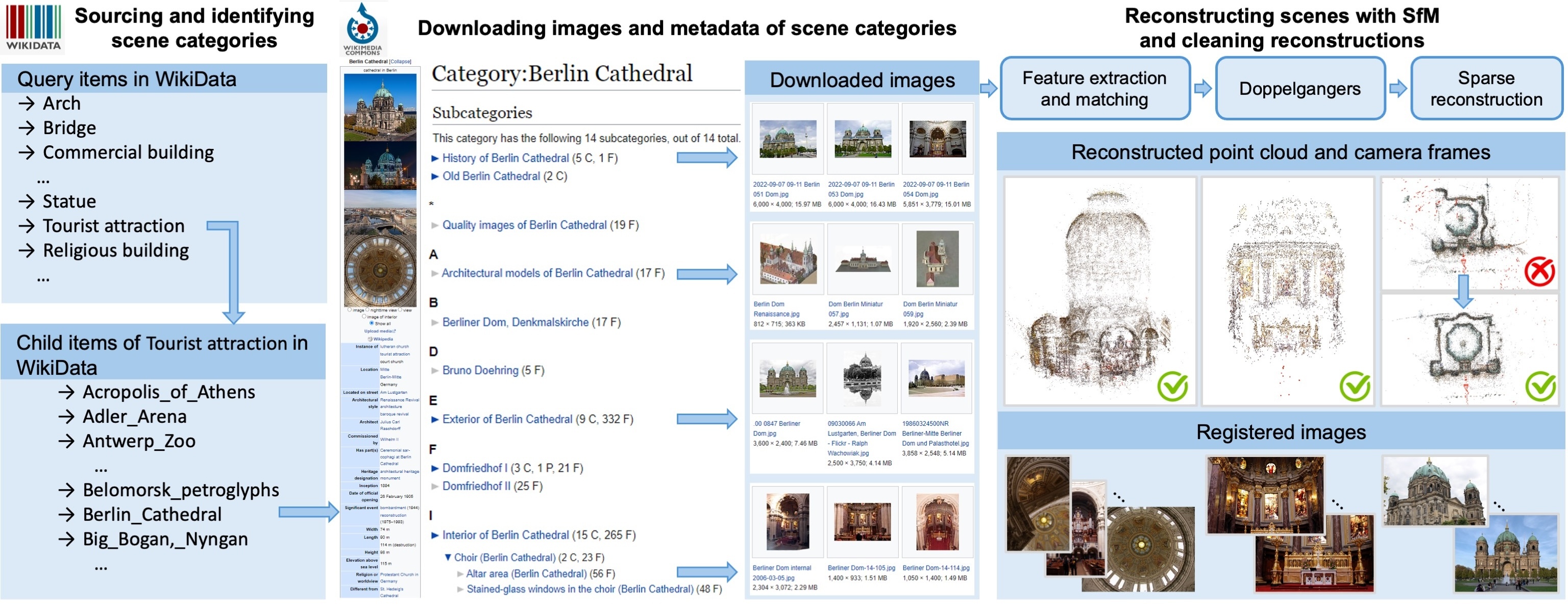
Conditioning on the Extrinsic Matrix
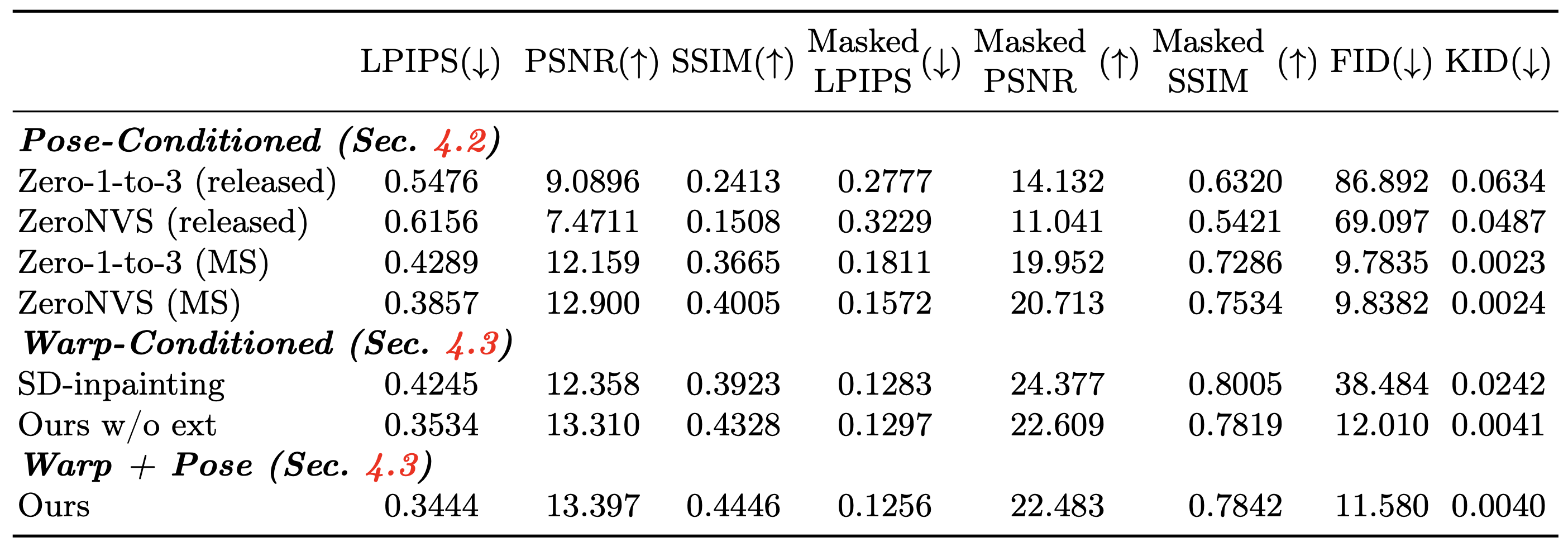
Simply finetuning pose-conditioned diffusion models, such as ZeroNVS, signficantly improves their generalization to in-the-wild scenes. However, the depth and scale of the scene in ZeroNVS is ambiguous and requires manual tuning.